Centralizar & Organizar los mejores artículos de Seguridad informática.
18- 79.400 URLs de Gmail indexadas en Google no son un leak
Ya he escrito varias veces de este comportamiento tan curioso que tienen los buscadores a la hora de indexar contenido en la base de datos. Lo he hecho con Facebook y también lo hice con WhatsApp, así que no va a ser nada nuevo para nadie lo que os voy a contar, salvo que he aplicado la misma metodología a Gmail, buscando qué se queda indexado en Google que provenga de correos de Gmail.
Lo primero de todo, como no, es comprobar que el fichero robots.txt de Gmail está correctamente configurado – y por https y todo -. Si entráis en él, podréis ver un montón de cosas Disallow. Entre los directorios prohibidos está el directorio /u/ pero no el directorio /mail/u/ que es donde los usuarios visualizan todos sus mensajes de correo.
 |
| Figura 1: Robots.txt de Gmail no bloquea /mail/u/ |
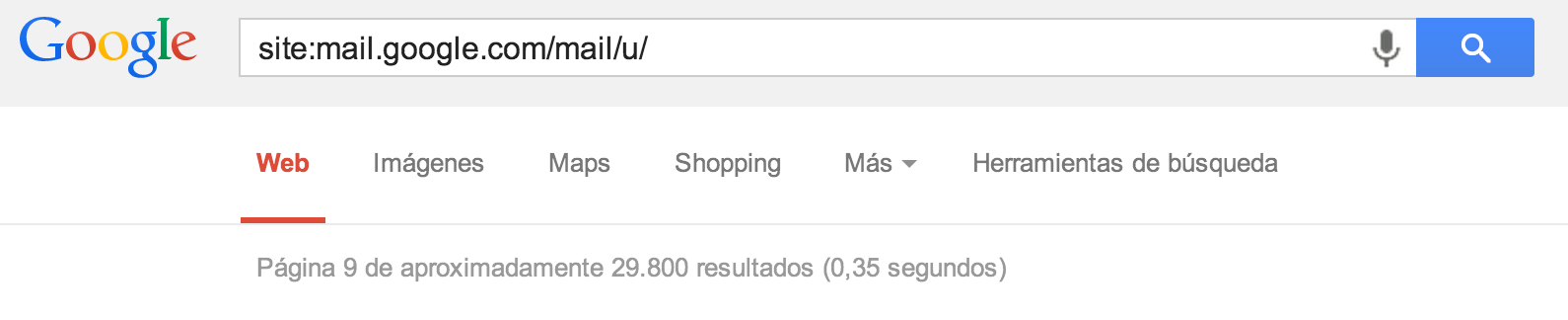
Lo siguiente es evidente, buscar qué URLs de esa ruta han caído indexadas enGoogle, para lo que basta un simple site:mail.google.com/mail/u/ para ver qué sale. Eso sí, después de la búsqueda hay que dar a la opción de “Mostrar todos los resultados“.
 |
| Figura 2: Hay aproximadamente 79.400 URLs indexadas |
Entre las cosas que salen entre esos 79.400 resultados indexados, están las URLsde mensajes que venían con números de teléfono enlazados, y pueden localizarles en el título de las URLs. No sabemos de qué usuario es ese número, pero Google lo tiene indexado.
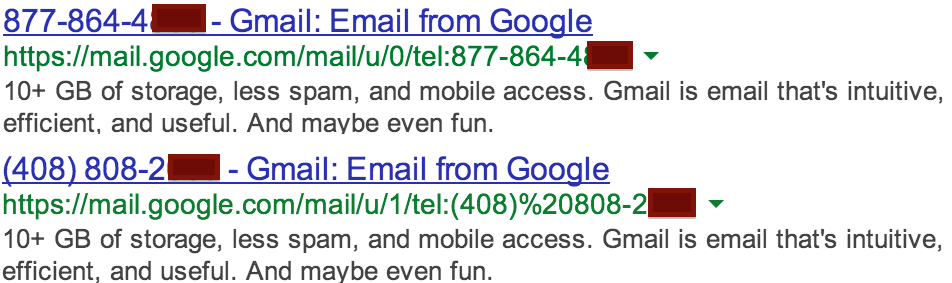 |
| Figura 3: URLs con números de teléfono indexados en Google |
En otro orden de cosas curiosas aparecen URLs para la descarga de ficheros adjuntos, que aunque no están cacheados, sí que queda la URL en la caché con el título del documento, tal y como puede verse en este ejemplo.
 |
| Figura 4: URL con fichero adjunto relativo a un ”Curso de receitas” |
El número de URLs es enorme, así que puedes perder tiempo buscando entre lo que allí hay, para ver si encuentras algo más “curioso” en el nombre del adjunto o el título, ya que quedan indexados ambos.
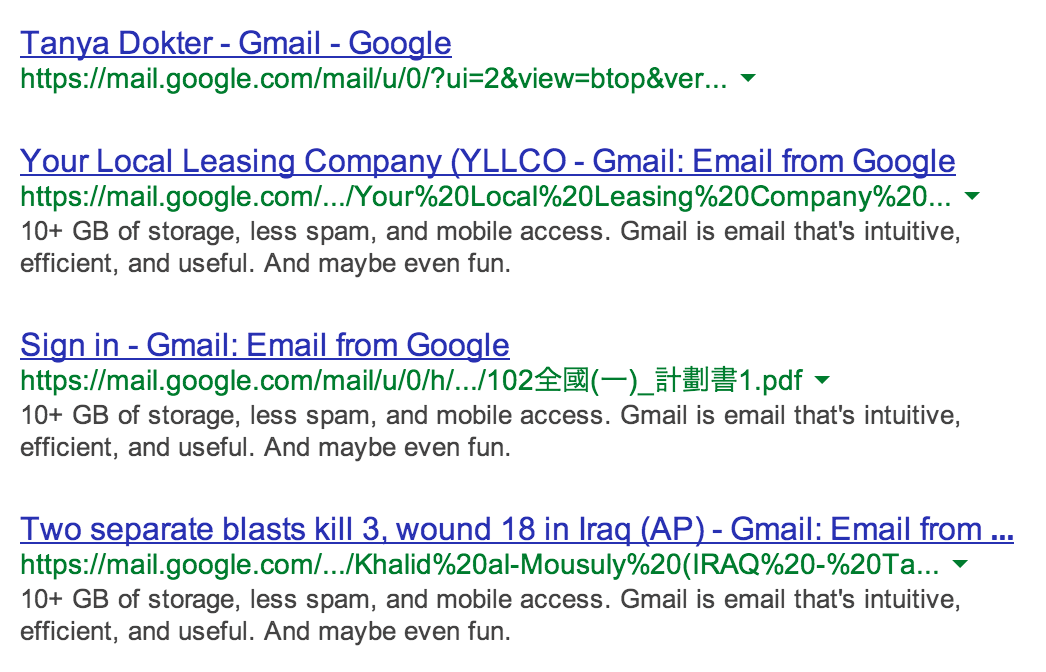 |
| Figura 5: URLs con adjuntos de todo tipo, hasta con noticias de IRAQ |
Hablé sobre esto con la gente de seguridad de Google, para decirles que podría ser un detalle higiénico que en lugar de dejar estos leaks de información, aplicaran lo que Google dice que hay que aplicar para evitarlos, es decir, aplicar robots.txt, lameta tag de NoIndex o el header HTTP X-Robots-tag NoIndex, pero han dicho que prefieren no hacerlo.
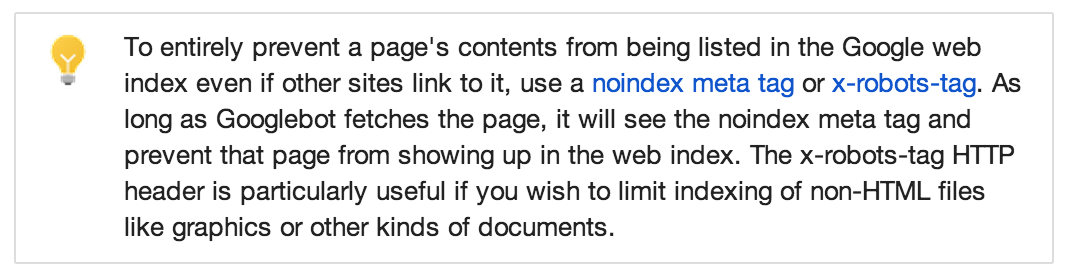 |
| Figura 6: Opciones para evitar indexación de URLs y Títulos recomendadas por Google |
¿Y si por error cae indexado una URL con un fichero adjunto que tiene un título o un nombre demasiado significativo y quieres eliminarlo? Pues no puedes usar lasHerramientas del Webmaster y deberías pedírselo directamente a ellos.
 |
| Figura 7: ¿Hoy indexo menos que ayer pero más que mañana? |
Curioso, ¿no? Pues lo más curioso es que hoy he ido a buscar otra vez y se han perdido unas 50.000 URLs de la base de datos… como lágrimas en la lluvia. Curioso, ¿verdad?Actualización: Ahora quedan menos URLs…
 |
| Figura 8: A las 22:55 de la noche salen solo 15.200 URLs indexadas |
Acutalización 2: A día 6 de Noviembre solo quedan 14.700
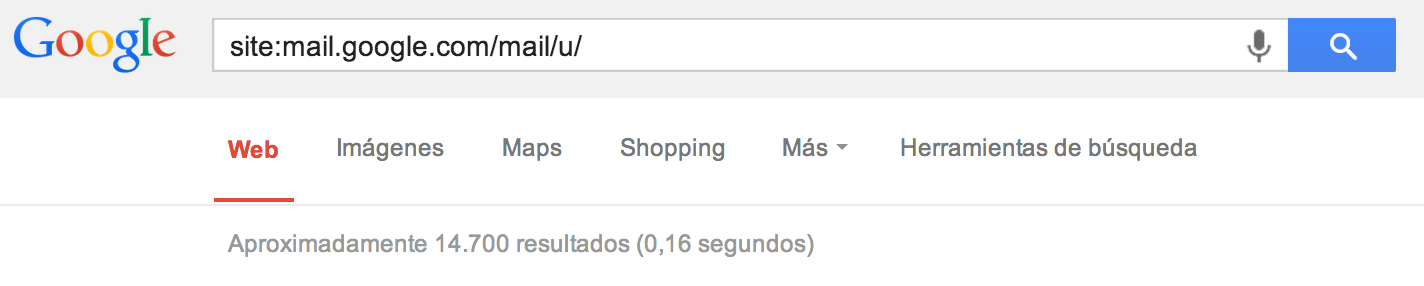 |
| Figura 9: ¿Morirán todas? |
Saludos Malignos!
Publicaciones Anteriores
Publicaciones Siguiente
Los comentarios están cerrados.
