Centralizar & Organizar los mejores artículos de Seguridad informática.
17- Facebook tiene problemas con la indexación en Google
Muchas veces he expresado que no me parece nada claro la forma en la que los buscadores como Google o Bing piden a los webmasters que le indiquen si quieren que se indexe o no su contenido. Me parece que su política de indexo todo y si no quieren algo que lo digan es un poco abusiva, especialmente teniendo en cuenta que si alguien quiere scrappear sus resultados o indexarles a ellos no les gusta nada. De hecho, es bien conocido el problema que tuvo Google con los medios de comunicación online o las guerras legales con los Orphan Books cuando quisieron indexar todos los libros de las bibliotecas americanas escaneándolos.
Volviendo al tema de la indexación de contenidos y la forma de indicarle que no quieres que algo esté disponible, un webmaster que quiera que contenido de su web esté indexado en Google debe utilizar cuatro formas distintas para notificárselo al buscador, que son:
- Robots.txt: Para decirle a la araña del buscador que por favor no indexe el contenido de los archivos que se encuentran en determinados directorios. Esto no protege de que sea indexada la URL o el Título si s encontrado por otros medios.
- Etiqueta HTML Meta NoIndex: Es una etiqueta en código HTML para decirle a Google que, si un archivo ha sido indexado no porque lo haya encontrado la araña del buscador sino porque se ha seguido un enlace, que por favor no indexe su contenido, y tampoco las URLs o Títulos.
- HTTP Header X-Robots-Tag “Noindex”: Para los archivos que no son HTML – y donde no se puede poner una etiqueta HTML Meta – entonces debe ser el servidor Web el que envíe una cabecera para decirle que ese documento no debe ser indexado para nada. Es decir, ni su URL, ni su título, ni nada.
- Herramientas del Webmaster: Para pedir que una vez que esté indexado un documento en la base de datos – y en la caché – desaparezca, pues hasta que no se elimine, por mucho que se cambie la configuración seguirá estando disponible el contenido.
Y esto, no es nada fácil de entender para nadie, como tampoco lo es para grandes sitios como Facebook que se ven afectados por malas configuraciones. Además, estos cuatro métodos tienen problemas de base de implementación que paso a contaros aquí:
- Robotx.txt: Es un archivo que le dice a la araña qué no se quiere tener indexado. Esto puede ser por motivos de SEO, privacidad o seguridad. Sin embargo, le obliga al webmaster a descubrir sus partes “secretas” de la web a atacantes y para más INRI, el buscador indexa los robots.txt poniendo disponible esa información a atacantes.
- Etiqueta HTML Meta NoIndex: Sólo está disponible para archivos de tipo HTML, así que sólo se puede utilizar en una porción muy pequeña de los documentos de un sitio web. Quedan fuera los archivos gráficos, documentos ofimáticos, etcétera, lo que hace que esta etiqueta se use bastante poco.
- HTTP Header X-Robots-Tag “NoIndex”: Obliga a tener un nivel de administración del servidor web que habitualmente no se tienen en los servicios de Hosting. Solo aquellos que tengan acceso a la configuración del servidor web podrán utilizarlo.
- Herramientas del Webmaster: Obliga a tener una cuenta de servicio de Google, a reclamar el sitio como tuyo ante Google, y después se podrá pedir el retiro de una URL. Además no es inmediato y hay que esperar un tiempo.
Con todos estos handicaps de funcionamiento a la hora de gestionar la indexación o no de los contenidos de una web, es normal que hasta los grandes tengan problemas. Y lo podemos ver aquí en el caso de Facebook. Vamos punto por punto.
El robots.txt de Facebook
Si analizamos el fichero en cuestión veremos que Facebook hace un esfuerzo “grande” en su fichero robots.txt para conseguir ser indexado cómo él quiere por los buscadores. Es un archivo grande, estructurado por bots, y que además marca muy bien lo que no quiere que le indexen.
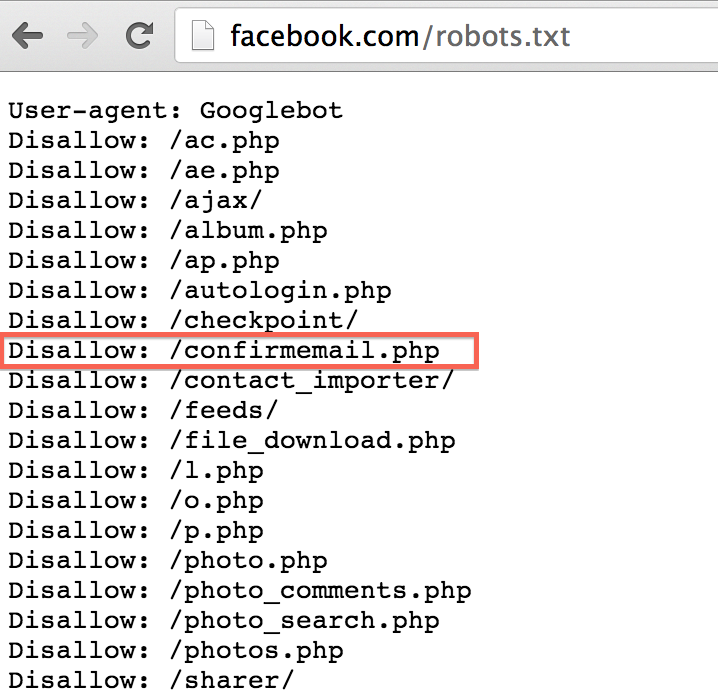 |
| Figura 1: Sección de robots.txt de Facebook para el bot de Google |
Por desgracia, ese fichero está siendo indexado, y cualquiera podría encontrar qué archivos backend PHP son los que más le preocupan a Facebook buscando dentro de él – a través de Google o revisándolo manualmente -.
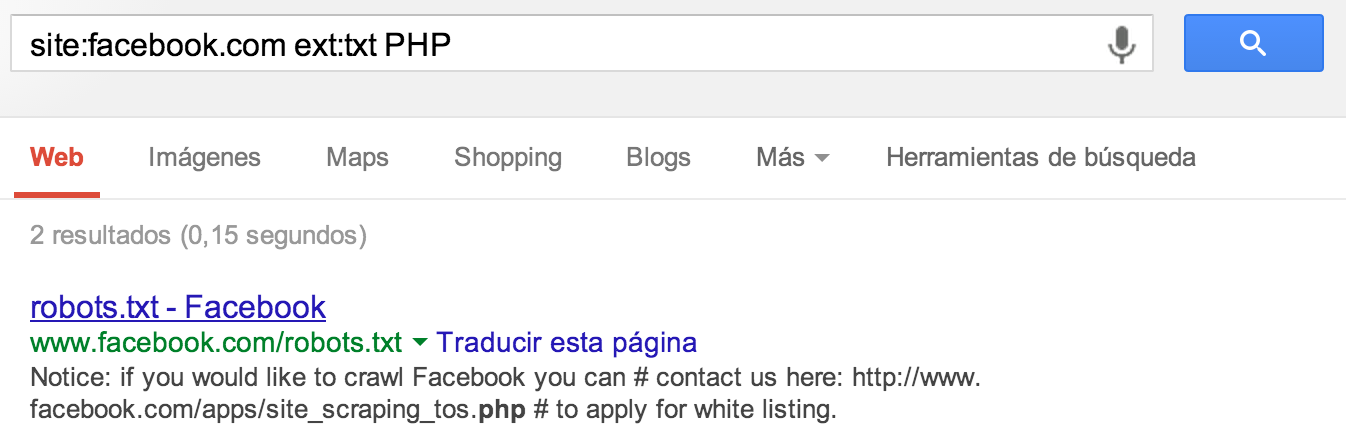 |
| Figura 2: El fichero robotx.txt indexado en Google |
Como podéis ver, hay un confirmemail.php que podría ser útil revisar a ver si está o no indexado en la base de datos del buscador, así que haciendo un poco de hacking con buscadores, preguntamos por URLs almacenadas de confirmemail.php enFacebook.
 |
| Figura 3: 4.750 URLs indexadas de confirmemail.php |
Como se puede ver, hay 4.750 registros de URLs de confirmemail.php indexadas con información de correos electrónicos de usuarios que se usan en el sitio para diversas funciones. Si buscamos por correos de Gmail.com, salen unos cientos, con las direcciones de correo indexadas.
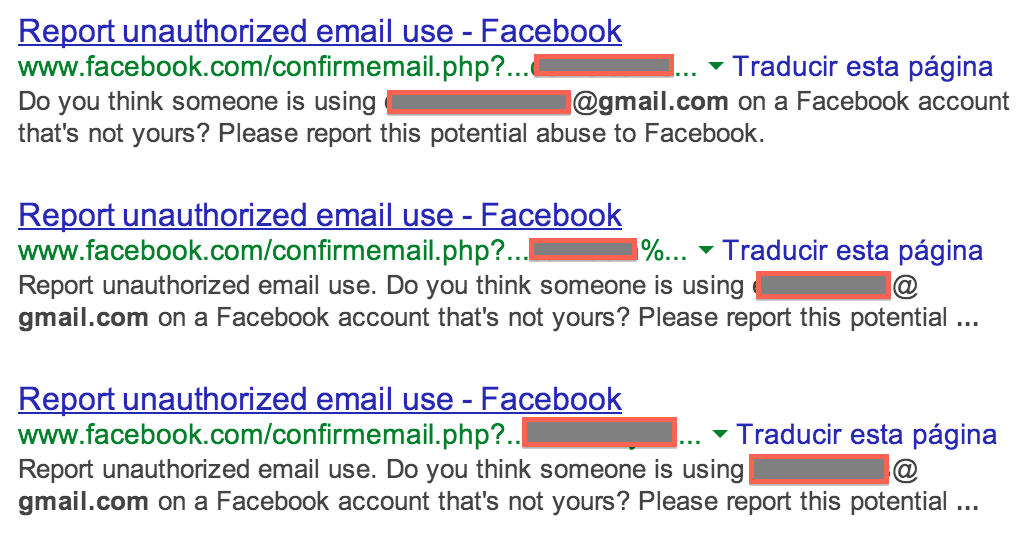 |
| Figura 4: Correos de Gmail indexados |
En ese caso, como podéis apreciar, Google está indexando el contenido de la página ya que sale el texto de la página en la descripción, y además lo cachea, así que no está funcionando bien la configuración del bloqueo de Confirmemail.php en el fichero robots.txt.
Meta tag HTML NoIndex, NoIndexImages, NoArchive
Si miramos el contenido del fichero confirmemail.php que devuelve el servidor con una de esas URLs indexadas, podremos ver que no se está haciendo uso de la Metatag NoIndex, NoArhive - para que no se guarde en caché – o NoIndexImages - para que las imágenes de la página tampoco queden indexadas -.
 |
| Figura 5: La página confirmemail.php no hace uso de etiquetas Meta para evitar indexación y caching |
Mi impresión personal es que es simple desconocimiento de todas las formas de hablar con Google para elegir una mejor indexación y los problemas de privacidad que esto puede conllevar, pero puede ser que exista algún motivo que yo desconozco.
HTTP Header X-Robots-Tag “NoIndex”
Este problemas de indexación de información se extiende también a las URLs de las fotografías o documentos ofimáticos. Si buscamos por cosas que aparecen en los servidores de la CDN que utiliza Facebook, aparecerán URLs diversas, todas ellas filtradas por el fichero robots.txt.
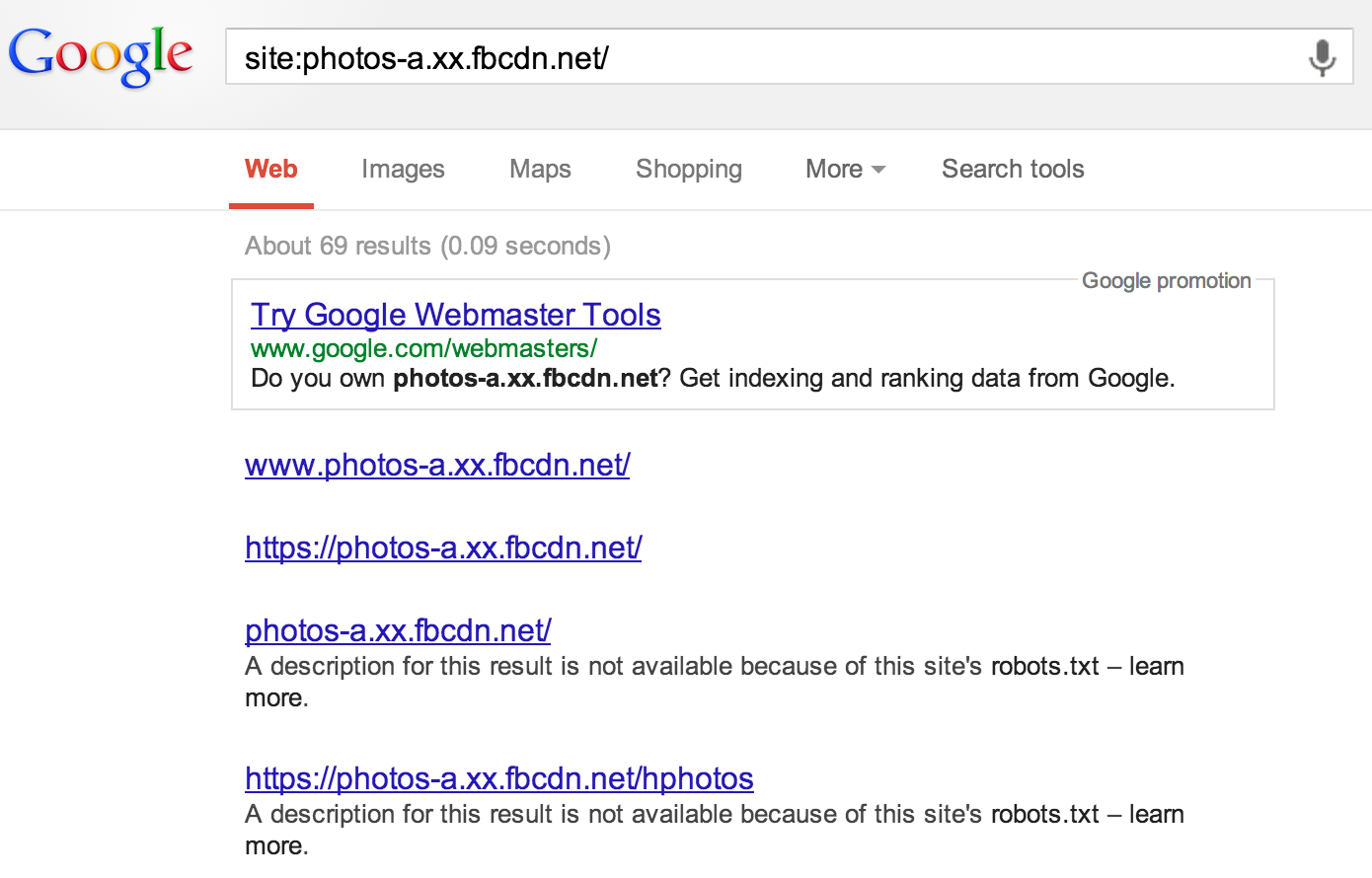 |
| Figura 6: URLs de la CDN de Google indexadas, pero filtradas por robots.txt |
Esto es algo que como se puede ver, Google detecta ya como extraño, y saca un anuncio con las Herramientas del Webmaster para indicar que si se desea borrar este contenido, el único camino es sacarse la cuenta de Google, reclamar el sitio como tuyo, y pedir el borrado de todas esas URLs.
El que aparezcan todas esas URLs indica que Facebook no está haciendo uso de las etiquetas X-Robots-Tag “NoIndex” en el envío de los contenidos, así que Google las introduce en los resultados y listo.
Herramientas del Webmaster: El parámetro n_m
Viendo que Facebook no se lleva muy bien con las opciones de indexación deGoogle, mis compañeros de Eleven Paths que forman “el equipo de investigación”se dieron cuenta de que en la web de Facebook se utiliza un parámetro de nombren_m que lleva como valor la dirección de e_mail del usuario, y que se usa en direcciones URL que NO están filtradas por robots.txt y no hacen uso tampoco de laMeta Tag HTML NoIndex o ni del encabezado HTTP X-Robots-Tag “NoIndex”, por lo que aparecen muchas direcciones de correo en la caché del buscador.
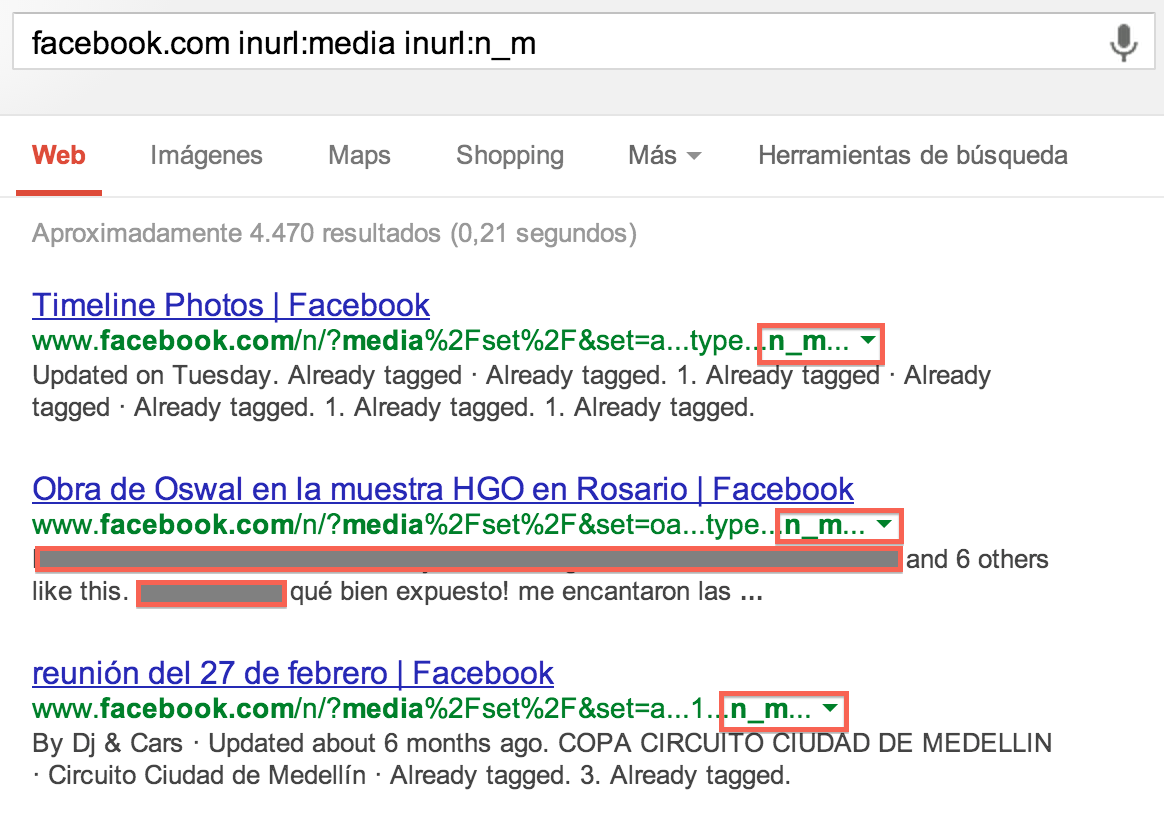 |
| Figura 7: URLs con el parámetro n_m indexadas en Google |
Como tampoco tienen ninguna protección para la caché con las etiquetas HTML o encabezados HTTP NoArchive aparecen también en ella, por lo que es fácil acceder a mucha información de lo que hacen los usuarios rastreando ese parámetro.
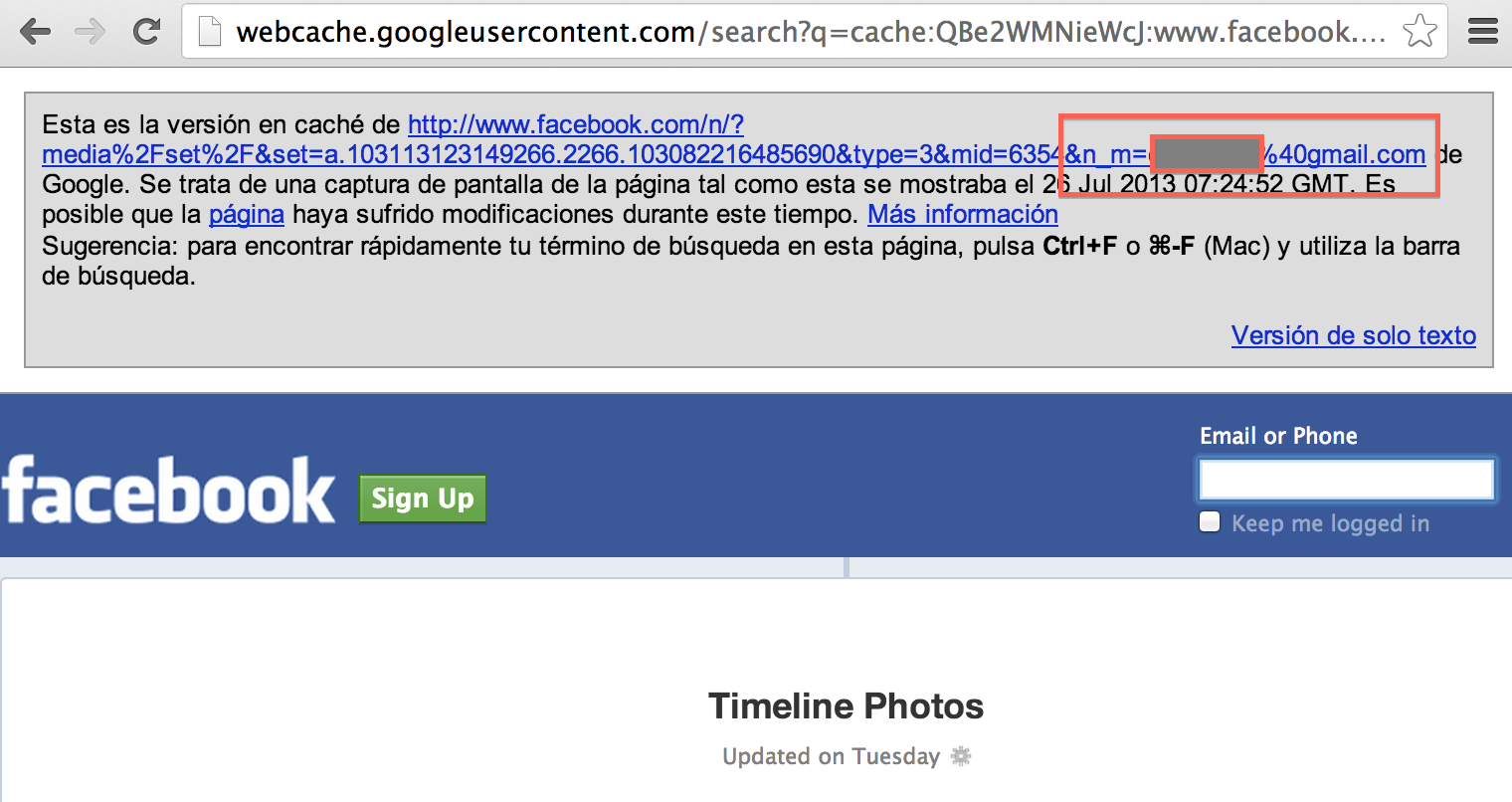 |
| Figura 8: Direcciones de correo en la caché de Google en parámetros n_m |
Si Facebook quiere limpiarlo de Google, no le queda otra que registrarse en el servicio de Herramientas del Webmaster y solicitar su borrado
Conclusiones
La existencia de 4 puntos distintos de configuración de las opciones de indexación de un buscador como Google pueden liar a Webmasters tan especializados comoFacebook, llevándoles a tener auténticos problemas de privacidad.
Por supuesto, también cuenta que el envío de datos sensibles por la URL es algo que como dije “podía ser tu perdición” y que no deja en buen lugar a Facebook, que espero tome buena nota de esto y consiga poner un poco de orden en lo que deja que se indexe o no de él.
Saludos Malignos!
Publicaciones Anteriores
Publicaciones Siguiente
Los comentarios están cerrados.
